import os
import traceback
import numpy as np
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, MaxPooling2D
from tensorflow import keras
from tensorflow.keras.models import load_model
from tensorflow.keras.datasets import mnist
participant_number = 20
def new_model():
model = Sequential()
model.add(Conv2D(10, (3, 3), input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(20, (3, 3)))
model.add(Flatten())
model.add(Dense(units=100, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy'],
optimizer=keras.optimizers.Adam(lr=0.001))
return model
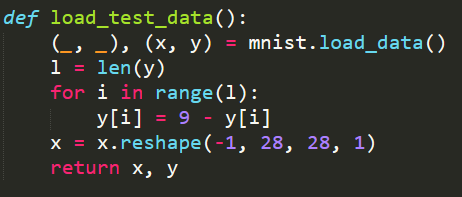
def load_test_data():
(_, _), (x, y) = mnist.load_data()
l = len(y)
for i in range(l):
y[i] = 9 - y[i]
x = x.reshape(-1, 28, 28, 1)
return x, y
def train_models():
(x, y), (_, _) = mnist.load_data()
x = x.reshape(-1, 28, 28, 1)
for i in range(participant_number):
model = new_model()
model.fit(x, y, batch_size=64, epochs=10)
model.save("model/"+str(i))
def aggregation(parameters):
print('aggregation')
weights = []
for layer in parameters:
sum = 0
l = len(layer)
for temp in layer:
sum = sum + temp
weights.append(sum / l)
model = new_model()
l = len(model.get_weights())
model.set_weights(weights)
return model
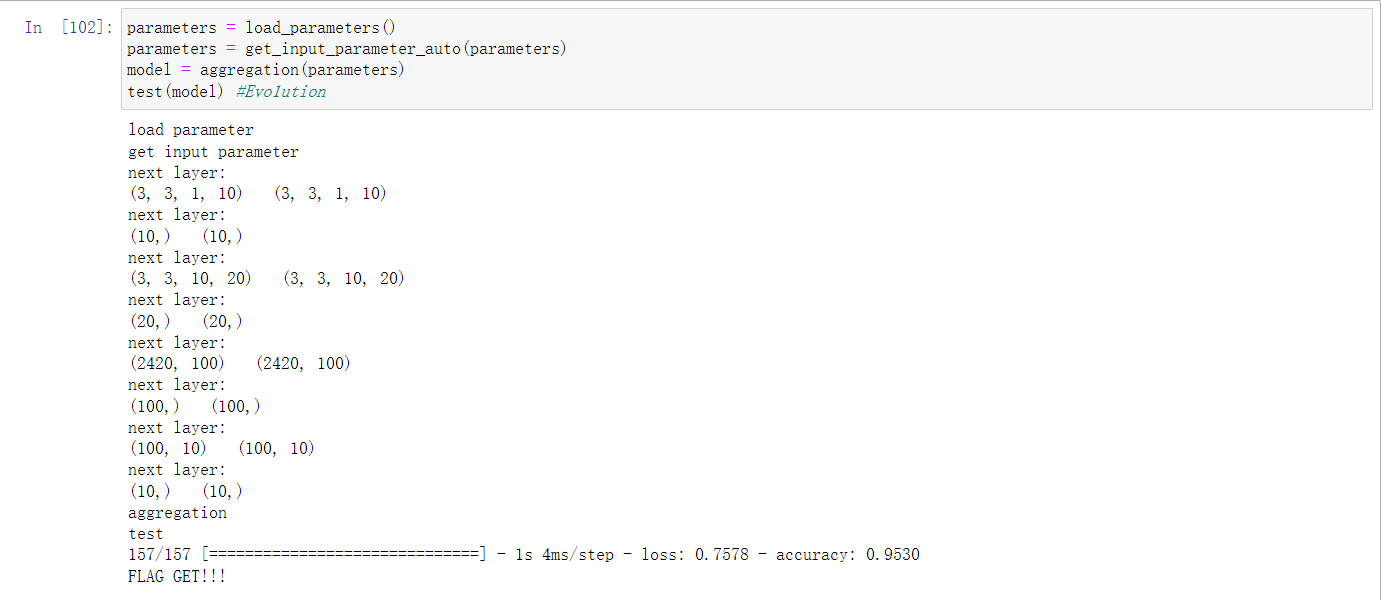
def test(model):
print('test')
my_x, my_y = load_test_data()
loss, acc = model.evaluate(my_x, my_y, batch_size=64)
if acc > 0.95:
print("FLAG GET!!!")
else:
print("you fail", acc)
def load_parameters():
print('load parameter')
parameters = []
models = []
for i in range(participant_number):
models.append(load_model("model/"+str(i)))
for i in range(8):
layer = []
for j in range(participant_number):
temp = models[j].get_weights()
layer.append(temp[i])
parameters.append(layer)
return parameters
def get_input_parameter_auto(parameters):
print('get input parameter')
myid = 0
for layer in parameters:
print("next layer:")
print(layer[0].shape," ",mylayers[myid].shape)
input_weight = mylayers[myid]
myid = myid + 1
layer.append(input_weight)
return parameters
if __name__ == '__main__':
if not os.path.exists('model'):
os.mkdir("model")
train_models()
dict_shape = {0:(3, 3, 1, 10), 1:(10,), 2:(3, 3, 10, 20), 3:(20,),
4:(2420, 100), 5:(100,), 6:(100, 10), 7:(10,)}
mylayers = []
for inde in range(8):
f = open(f'{inde}.txt',mode = 'r')
file = f.readlines()
mylayer = []
for item in file:
item = item.replace('\n','')
item = item.split(' ')
mylayer.append(item)
mylayer = mylayer[0]
mylayer = mylayer[0:-1]
for i in range(len(mylayer)):
mylayer[i] = float(mylayer[i])
pas = []
for num in range(len(dict_shape[inde])):
pas.append(int(dict_shape[inde][num]))
if (len(pas)==4):
mylayers.append(np.array(mylayer).reshape(pas[0],pas[1],pas[2],pas[3]))
elif(len(pas)==2):
mylayers.append(np.array(mylayer).reshape(pas[0],pas[1]))
elif(len(pas)==1):
mylayers.append(np.array(mylayer))
print(mylayers[inde].shape)
f.close()
parameters = load_parameters()
parameters = get_input_parameter_auto(parameters)
model = aggregation(parameters)
test(model)
|