
Auto-Traffic-Analysis
New Directions in Automated Traffic Analysis论文学习
文章主要信息
| 论文名称 | New Directions in Automated Traffic Analysis |
|---|---|
| 录用信息 | CCS 2021(CCF-A) |
| 作者 | Jordan Holland, Paul Schmitt, Nick Feamster, Prateek Mittal |
| 论文链接 | https://dl.acm.org/doi/10.1145/3460120.3484758 |
| 源码 | https://github.com/nprint/nprint |
| 数据集 | https://drive.google.com/drive/folders/158Lwb9TwopIJ0lGPuFik5744qPiqrg9F |
摘要
目前,机器学习技术被广泛应用于入侵检测、应用程序识别等网络流量分析任务中。但是,当我们使用机器学习方法时,特征提取、模型选择、参数调优等众多因素决定着模型的性能,每当面对不同的网络流量或新的任务,就需要研究人员重新考虑调整这些选项甚至重新建模,这个调整甚至是重建的过程往往需要大量人力成本和专业知识。并且,流量模式会不断的发生变化,使得模型和人工提取的特征过时。因此有必要为不同网络流量创建一个通用的表示,可以用于各种不同的模型,跨越广泛的问题类,并将整个建模过程自动化。该文关注通用的自动化网络流量分析问题,致力于使研究人员将更多的精力用于优化模型和特征上,并有更多的时间在实践中解释和部署最佳模型。
自动化网络流量分析
本文提出一种自动化流量分析方法(nPrintML),使机器学习技术更容易应用于更广泛的流量分析任务。nPrintML 包含 nPrint 流量表示和 AutoML 两部分,首先 nPrint 通过对 IP 数据包头进行对齐和拼接形成统一的数据表征,然后使用 AutoGluon-Tabular 框架进行自动化的进行特征提取、模型搜索和超参数优化。作者在 8 个不同的流量分析任务上对 nPrintML 进行评估,都取得了很好的效果。
数据表示 nPrint
对于流量分类问题,数据表示与模型选择同等重要,所以在应用机器学习方法时,如何对数据进行表示和编码是非常重要的一环。对于网络流量数据的编码需要满足以下4个要求:
- 完整的表示。我们的目标不是选择特定的特征,而是一种统一的数据编码,以避免依赖专家知识,所以需要保留包含包头在内的所有数据包信息;
- 固定的大小。许多机器学习模型的输入总是保持相同的大小,所以每个数据包表示都必须是常量大小;
- 固有的规范化。当特征被归一化后,机器学习模型通常会表现得更好,也能减少训练时间并增加模型的稳定性,所以如果数据的初始表示本身就是规范化的,将会非常方便;
- 一致的表示。数据表示的每个位置都应该对应于所有数据包包头的相同部分,也就是说,即使协议和报文长度不同,特定的特征总是在数据包中具有相同的偏移量,对齐后的数据都能让模型基于这样的前提来学习特征表示。
首先,来看一下传统的流量数据包头。
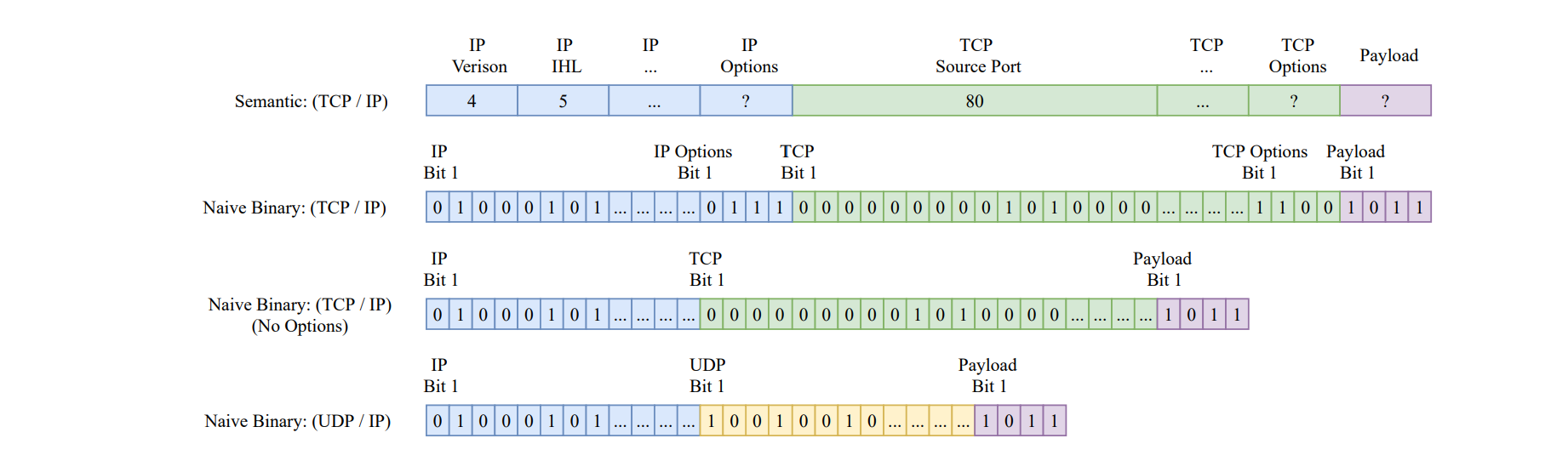
图1 语义表示法和朴素二进制表示法
如图1所示,网络流量表示的主要方式包括语义表示法和朴素二进制表示法。
- 语义表示法:每个报头都有各自的语义字段,但它不保留具有区分度的可选字段的顺序,同时需要领域专业知识来解析每个协议的语义结构,即使拥有这些知识,后续也还是不可避免进行繁琐的特征工程;
- 朴素二进制表示法:使用数据包的原始位图表示来保持顺序,但是忽略了不同的大小和协议,导致两个数据包的特征向量对同一特征具有不同的含义,这种不对齐可能会在重要特征的地方引入噪声而降低模型性能,同时也因为无法将每一位都映射到语义上而导致不可解释。
从图1中不难看出,不同的网络协议(如 TCP 和 UDP)有着不同的数据表示方案,甚至相同的网络协议(如 IP)也不相同(是否包含 Options 选项),这显然无法满足上述统一化数据表示的需求。因此,研究人员结合语义表示法和朴素二进制表示法提出一种统一的网络数据包表示方法nPrint(图 2)。
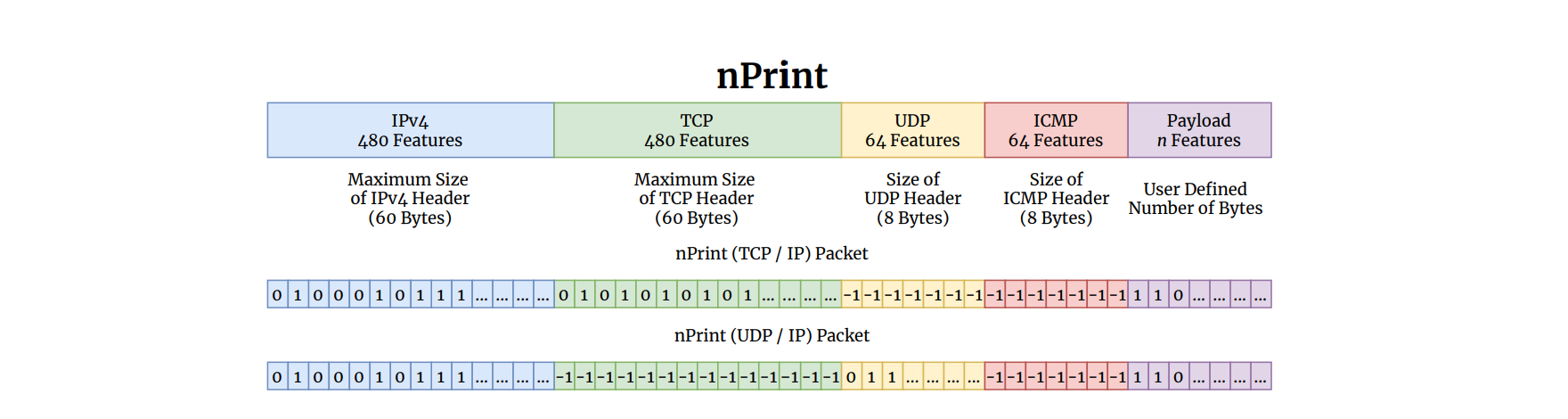
图2 nPrint
nPrint 使用每种协议允许的最大包头长度来表示该协议,同时将不同协议头部拼接组合成固定长度的包头。首先,它会保证任何数据包都可以被完整表示而不丢失任何信息;然后,使用内部填充确保每个数据包以相同数量的特征表示,并且每个特征具有相同含义,这种在位级上可解释的表示使我们能够更好的理解模型;其次,直接使用数据包的位,区分于某个位被设置为0,将不存在的包头用-1填充;最后,每个数据包都用相同数量的特征表示,对于给定的网络流量分析任务,将载荷设置为可选的字节数。此外,nPrint具有模块化和可扩展的特性,不仅可以将其他协议添加到表示中,也可以将一组数据包表示串联起来构建多包的nPrint指纹。
因此,nPrint 符合了4大性质:
- 完整性:理论上可以包含所有协议
- 不变性:数据表征可以是一个确定的长度
- 归一性:数据被表示为 1/0/-1
- 一致性:不同数据包头的同一选项在同一位置
nPrintML
作者将 nPrint 与 AutoGluon-Tabular 框架相结合,提出 nPrintML,实现了实现了机器学习流程的自动化(如图3所示)。
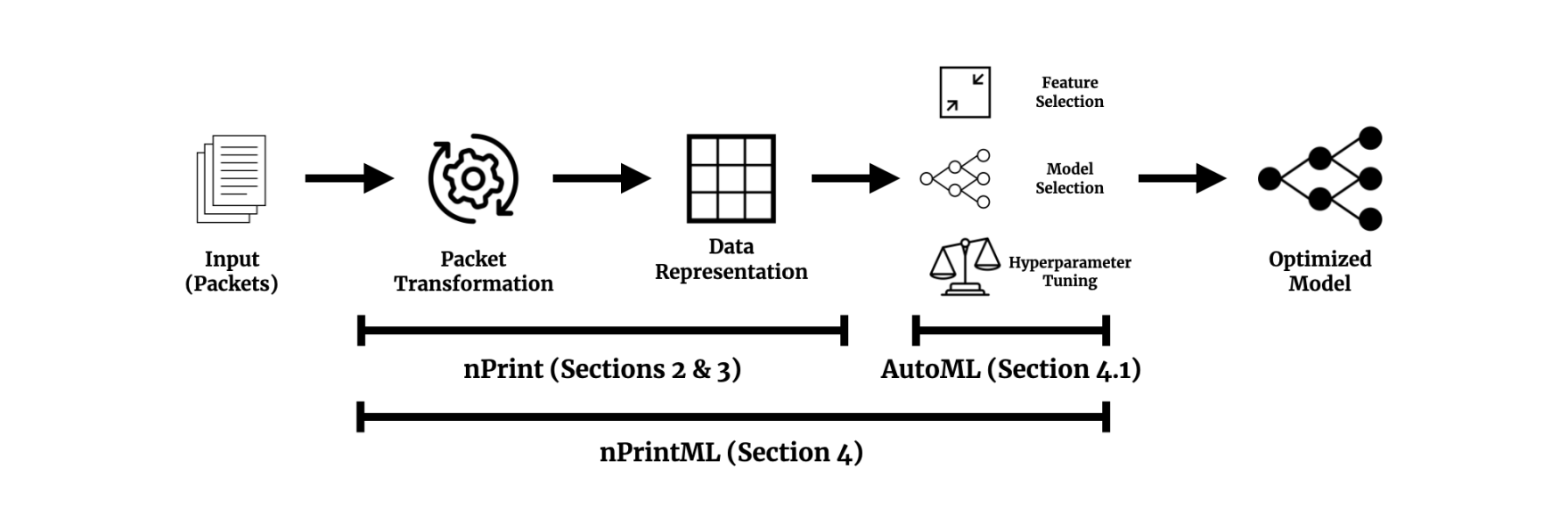
图3 nPrintML
AutoGluon背后技术:https://www.bilibili.com/video/BV1F84y1F7Ps?spm_id_from=333.999.0.0
AutoGluon在Windows下安装:https://www.bilibili.com/video/BV1yL4y177hH/?spm_id_from=333.788
实验结果
总览
针对8个网络流量分析场景,图4展示了用nPrintML进行分析的案例研究,实验结果表明,nPrintML不仅可以解决不同场景的网络流量分析问题,并且具有相较于传统方法更好的性能。
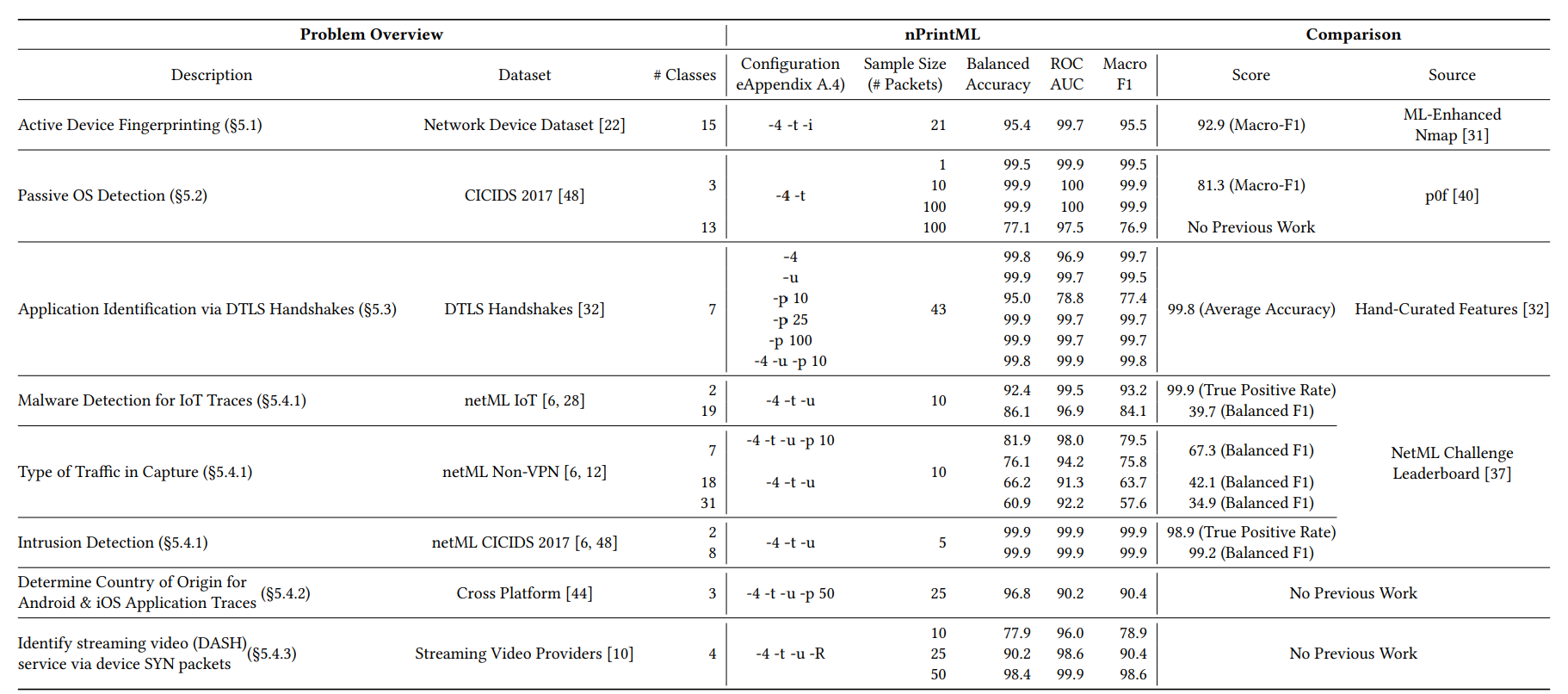
图4 实验结果总览
总结
将机器学习应用于网络安全中的流量分析任务的有效性取决于特征的选择和适当的表示,即不超过模型本身。本文为自动流量分析创建了一个新方向,提出了 nPrint,这是一种统一的数据包表示,它将原始网络数据包作为输入,并将其转换为适合表示学习和模型训练的格式,从而使机器学习过程的一部分自动化到目前为止,这在很大程度上是艰苦的和手动的。这种标准格式可以轻松地将网络流量分析与最先进的自动机器学习 (AutoML) 管道集成。 nPrintML 是 nPrint 与 AutoML 的集成,可自动学习相应任务的最佳模型、参数设置和特征表示。本文作者们将 nPrintML 应用于八种常见的网络流量分析任务,在许多情况下改进了最新技术。 nPrint 已经证明,许多网络流量分类任务都可以自动化,尽管存在许多未解决的问题,例如涉及多个流的自动时间序列分析和分类。 nPrint 最终应该应用于更大的分类问题集。
代码阅读及复现
(过两天再做……)
参考:
[1] Nick Erickson, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pedro Larroy, Mu Li, and Alexander Smola. 2020. AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data. arXiv preprint arXiv:2003.06505 (2020).
[2] Holland J , Schmitt P , Feamster N , et al. New Directions in Automated Traffic Analysis. 2021 ACMComputer and Communications Security Conference [C]. 2021.
[3] https://blog.csdn.net/WellShark/article/details/122192656

