Python爬虫学习 整理了一下以前写过的一些小爬虫。
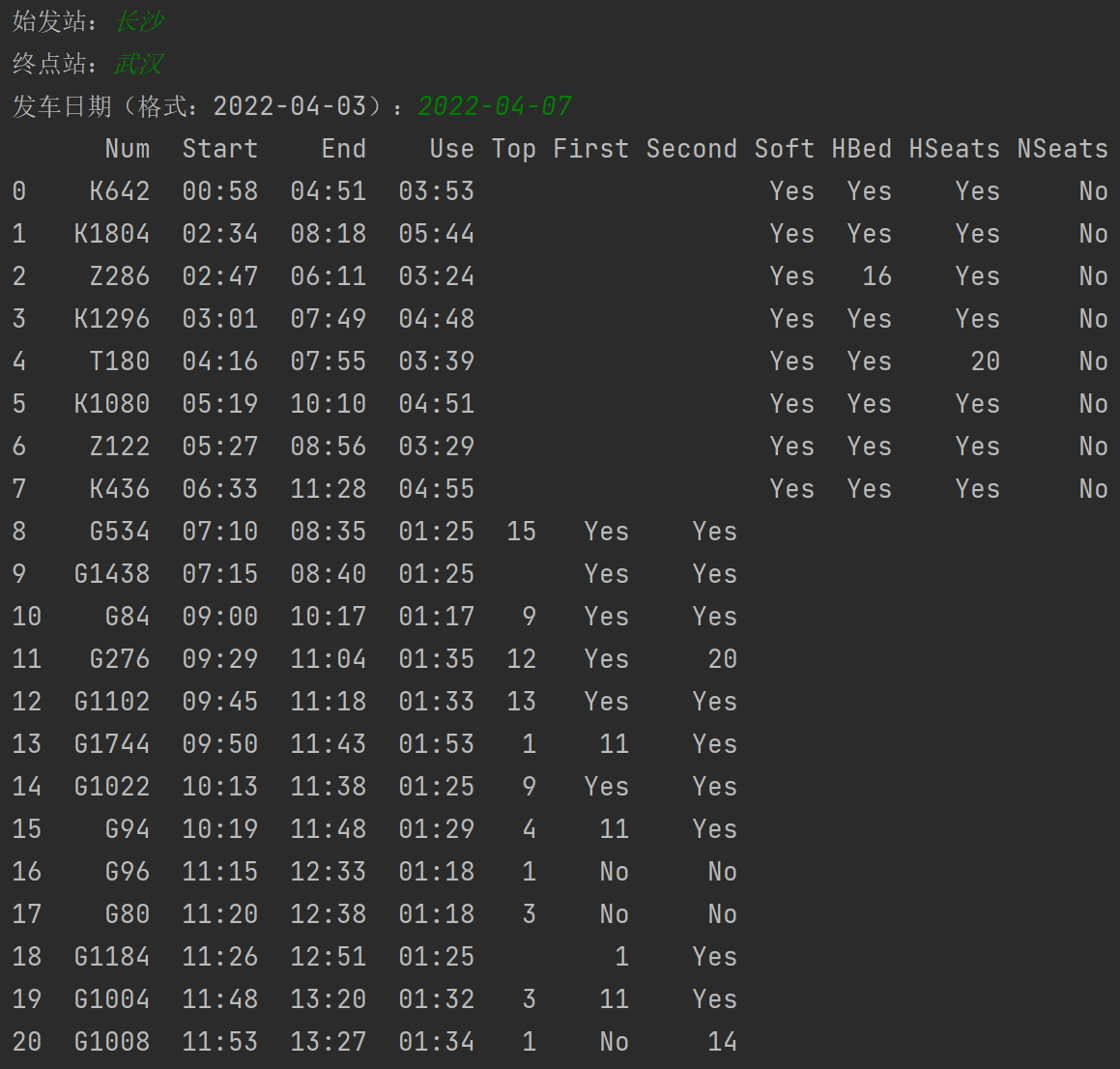
12306查票 import requestsimport pandas as pdimport jsonf = open ('stations.json' ,mode='r' ,encoding='utf-8' ) text = f.read() city_json = json.loads(text) f.close() from_station = input ('始发站:' ) to_station = input ('终点站:' ) train_date = input ('发车日期(格式:2022-04-03):' ) url = "https://kyfw.12306.cn/otn/leftTicket/query" data = { 'leftTicketDTO.train_date' : train_date, 'leftTicketDTO.from_station' : city_json[from_station], 'leftTicketDTO.to_station' : city_json[to_station], 'purpose_codes' : 'ADULT' } headers ={ 'Cookie' : '_uab_collina=164896135403377792450208; JSESSIONID=843F9AA2FC700ED2B8E8655CBA8E4AFD; BIGipServerotn=468713994.50210.0000; BIGipServerpool_passport=182714890.50215.0000; highContrastMode=defaltMode; guidesStatus=off; cursorStatus=off; RAIL_EXPIRATION=1649305414970; RAIL_DEVICEID=i7hoNlwMechBKbH0Ghsk6cswUh1nhyGKgfThBDYYiAGy_zBKBevr3wq6zqlS1GV-JvK0B-qVEYwihXSg-WVTUlOcG7NgUJc2INRx-UN6MMxdgg6sumeKjo2NXUwAOlNL7uSajwkmH4Aleee-puGjfAVFL2aVyYMY; route=9036359bb8a8a461c164a04f8f50b252; _jc_save_toStation=%u957F%u6C99%2CCSQ; _jc_save_fromDate=2022-04-03; _jc_save_toDate=2022-04-03; _jc_save_wfdc_flag=dc; _jc_save_fromStation=%u6B66%u6C49%2CWHN' , 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36' } response = requests.get(url=url,params=data,headers=headers) response.encoding = response.apparent_encoding result = response.json()['data' ]['result' ] lis = [] for index in result: index_list = index.replace('有' ,'Yes' ).replace('无' ,'No' ).split('|' ) TrainNum = index_list[3 ] StartTime = index_list[8 ] EndTime = index_list[9 ] UseTime = index_list[10 ] if ('G' in TrainNum): BussinessSeats = index_list[32 ] FirstSeats = index_list[31 ] SecondSeats = index_list[30 ] di = { 'Num' : TrainNum, 'Start' : StartTime, 'End' : EndTime, "Use" : UseTime, "Top" : BussinessSeats, "First" : FirstSeats, "Second" : SecondSeats, "Soft" : '' , "HBed" : '' , "HSeats" : '' , "NSeats" : '' } else : SoftBeds = index_list[23 ] HardBeds = index_list[28 ] HardSeats = index_list[29 ] NoSeats = index_list[26 ] di = { 'Num' : TrainNum, 'Start' : StartTime, 'End' : EndTime, "Use" : UseTime, "Top" : '' , "First" : '' , "Second" : '' , "Soft" : SoftBeds, "HBed" : HardBeds, "HSeats" : HardSeats, "NSeats" : NoSeats } lis.append(di) pd.set_option('display.max_rows' ,None ) content = pd.DataFrame(lis) print (content)
生成stations.json文件:
import timeimport jsonimport requestsfrom requests.exceptions import RequestException def getResponse (url ): try : headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } response = requests.get(url,headers = headers) if response.status_code == 200 : return response return None except RequestException: return None if __name__ == "__main__" : url = "https://kyfw.12306.cn/otn/resources/js/framework/station_name.js" data = getResponse(url) if data is not None : dict_data = {} text = data.text str_split = text.split('@' ) for chars in str_split[1 :]: station = chars.split('|' ) dict_data[station[1 ]] = station[2 ] with open ("stations.json" ,'w' ,encoding = 'utf-8' ) as fp: json.dump(dict_data,fp,ensure_ascii = False )
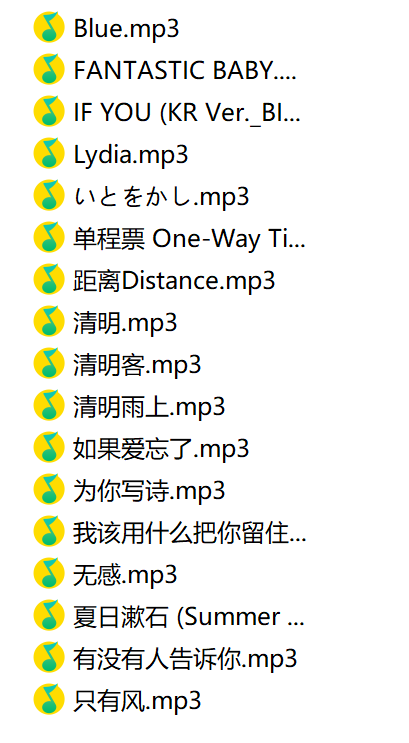
网易云热歌爬取 import requestsimport reimport osdef change_name (name ): new_name = re.sub(r'[\/\\\:\*\?\"\<\>\|\✩\˚\*\•̩̩͙ʚ]' ,'_' ,name) return new_name filename = "music\\" if not os.path.exists(filename): os.mkdir(filename) url = "https://music.163.com/discover/toplist?id=19723756" headers = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36' } response = requests.get(url=url,headers=headers) html_data = re.findall('<li><a href="/song\?id=(\d+)">(.*?)</a>' ,response.text) for music_id,music_name in html_data: music_url = f"https://music.163.com/song/media/outer/url?id={music_id} .mp3" music_content = requests.get(url=music_url,headers=headers).content music_name = change_name(music_name) with open (filename + music_name +'.mp3' ,mode='wb' ) as f: f.write(music_content) print (music_id,music_name)
MP3文件保存在music文件夹下:
古诗词爬取 import requestsimport reimport osurl = "https://www.oh100.com/shici/1127009.html" headers = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36' } response = requests.get(url=url,headers=headers) response.encoding = response.apparent_encoding li = re.findall("\d+?、(.*?)</p><p>" ,response.text) li[-1 ] = re.sub(r"</p><script>s\(\"content_relate\"\)\;\<\/script\>\<p\>\【形容洒脱的诗词\】相关文章\:" ,"" ,li[-1 ]) for se in li: print ("- " +se)
壁纸爬取 import requestsimport reimport os""" 整体思路: 1、访问网站查看信息(F12不可用可以先在别的网页打开再访问该网址) 2、进入对应tag观察request的headers等信息(注意要点击加载更多后再看XHR下的文件) 3、进入特定照片观察信息 4、在text属性中获取title、img_url等信息 5、在本地保存下来 """ filename = "img\\" if not os.path.exists(filename): os.mkdir(filename) def change_title (name ): new_name = re.sub(r'[\/\\\:\*\?\"\<\>\|]' ,'_' ,name) return new_name for page in range (1 ,6 ): url = f"https://m.bcoderss.com/tag/%e7%be%8e%e5%a5%b3/page/{page} /" headers = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36' } response = requests.post(url=url,headers=headers) href = re.findall('<li><a target="_blank" href="(.*?)"' ,response.text)[2 :] for index in href: response_1 = requests.get(url=index,headers=headers) title = re.findall("<title>(.*?)</title>" ,response_1.text)[0 ] title = change_title(title) img_url = re.findall('<img alt=".*?" title=".*?" src="(.*?)">' ,response_1.text)[0 ] img_content = requests.get(url=img_url,headers=headers).content with open (filename + title + '.jpg' ,mode='wb' ) as f: f.write(img_content) print (title,img_url)
壁纸会保存在img文件夹下(图片不是很适合放出来,就放下文字吧…)
LOL英雄皮肤图片爬取 import requestsimport reimport osheaders = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36' } def change_name (name ): new_name = re.sub(r'[\/\\\:\*\?\"\<\>\|\✩\˚\*\•̩̩͙ʚ]' ,'_' ,name) return new_name def save_img (name,title,skin_name,skin_url ): filename = f'{name+title} \\' if not os.path.exists(filename): os.mkdir(filename) content = requests.get(url=skin_url,headers=headers).content newname = change_name(skin_name) with open (filename+newname+'.jpg' ,mode='wb' ) as f: f.write(content) print (skin_name) hero_list_url = "https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2748291" response = requests.get(url=hero_list_url,headers=headers) hero_list = response.json()['hero' ] for hero in hero_list: hero_id = hero['heroId' ] hero_name = hero['name' ] hero_title = hero['title' ] hero_url = f"https://game.gtimg.cn/images/lol/act/img/js/hero/{hero_id} .js" response_1 = requests.get(url=hero_url,headers=headers) print (hero_id,hero_name,hero_title) skin_list = response_1.json()['skins' ] for skin in skin_list: if (skin['mainImg' ]): skin_url = skin['mainImg' ] skin_name = skin['name' ] save_img(hero_name,hero_title,skin_name,skin_url)
各个英雄的皮肤会保存在自己的文件下:
王者荣耀英雄皮肤爬取 import requestsimport reimport osimport jsondef change_name (name ): new_name = re.sub(r'[\/\\\:\*\?\"\<\>\|\✩\˚\*\•̩̩͙ʚ]' ,'_' ,name) return new_name def save_img (name,title,skin_name,skin_url ): filename = f"{title+name} \\" if not os.path.exists(filename): os.mkdir(filename) content = requests.get(url=skin_url,headers=headers).content with open (filename+skin_name+'_' +name+'.jpg' ,mode='wb' ) as f: f.write(content) headers = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36' } herolist_url = "https://pvp.qq.com/web201605/js/herolist.json" herolist = requests.get(url=herolist_url,headers=headers).json() for hero in herolist: hero_ename = hero['ename' ] hero_name = hero['cname' ] hero_title = hero['title' ] print (hero_ename,hero['cname' ]) if ('skin_name' in hero): skin_list = hero['skin_name' ].split('|' ) else : hero_url = f"https://pvp.qq.com/web201605/herodetail/{hero_ename} .shtml" response = requests.get(url=hero_url,headers=headers) response.encoding = response.apparent_encoding tu = re.findall('<ul class=\"pic-pf-list pic-pf-list3\" data-imgname=\"(.*?)\&0\|(.*?)\&0\|(.*?)\&72\">' ,response.text) skin_list = list (tu[0 ]) skin_lens = len (skin_list) for i in range (skin_lens): skin_url = f"https://game.gtimg.cn/images/yxzj/img201606/heroimg/{hero_ename} /{hero_ename} -bigskin-{i+1 } .jpg" skin_name = skin_list[i] save_img(hero_name,hero_title,skin_name,skin_url) print (skin_name,hero_name)
文件保存思路与LOL一致:
未完待续……